Pytest Fixtures: How to Use & Organize them in your Test Architecture
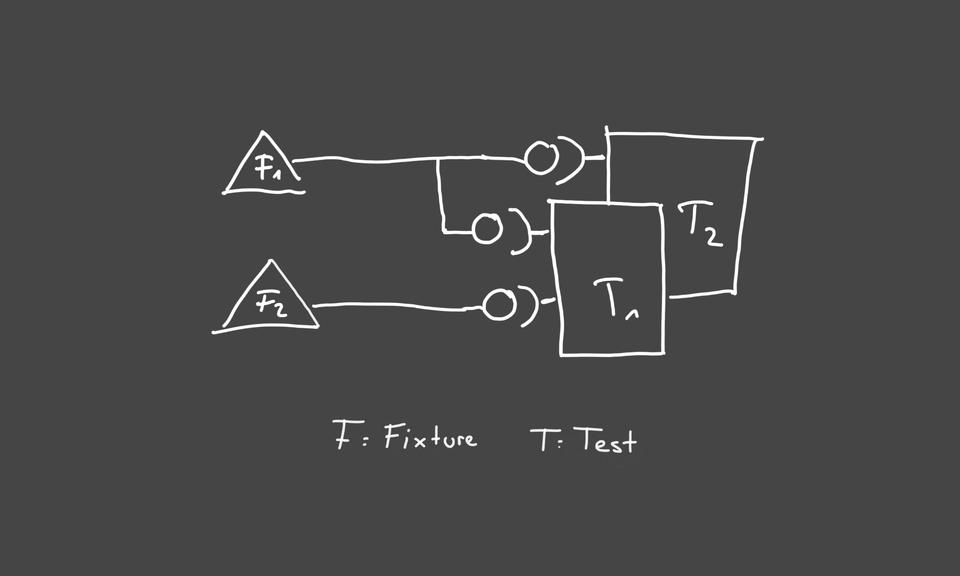
In my last post, I talked about why I practice TDD and why I want to share my learning progress in testing. Today I want to talk about what pytest fixtures are, when I use them and how you can share fixtures across your tests.
What are pytest fixtures?
Imagine you are writing a test for a function called validate_user(user: User) to the test. Of course, you need a user for this. Assume the user is defined as follows:
from dataclasses import dataclass
@dataclass
class User:
name: str
email: str
You would create the user in your test function and then pass it to the function you want to test:
def test_valid_user():
user = User(name="Patrick", email="[email protected]")
result = validate_user(user)
assert result.is_valid == True
So far, so good. If you want to test another function that checks the correctness of the email, you need to write a new test function that creates and tests the user again. This is where the fixtures come into play. Instead of doing that, you write a fixture that returns a User.
For example:
@pytest.fixture()
def user_fixture():
return User(name="Patrick", email="[email protected]")
def test_valid_user(user_fixture):
result = validate_user(user)
assert result.is_valid == True
def test_valid_email(user_fixture):
result = validate_email(user)
assert result.is_valid == True
That's the actual idea behind it. A small side note: testing is not just about increasing test coverage, but also about finding bugs. This means that in a real application, I wouldn't just test with one user object, but with a set of users with different name and email encodings, where I want to see if the functions behave as they should. Among other things, I would of course also like to test whether an invalid name or an invalid email leads to a false result.
When should I use Fixtures?
Roughly, this can already be seen from the example. pytest itself says that fixtures provide context for a test function. This can be, for example, the context for a database or the enrichment of your test data. I use it very often for both. As soon as I realize that data within a test can also be used in another test, I turn it into a fixture. If you come from another language, e.g. Java, you will most likely see the similarity to the setup/teardown functionality. pytest describes the comparison on their website very well and better than I could. Note: pytest also offers the option to choose a typical setup tear down style.
Differentiation between Error vs Failure
Normally, if a test fails or raises an exception, it gets the status “failed”. However, if a fixture raises an exception, pytest declares this as Error and not as “Failed”. pytest describes that the Error status is intended to indicate that pytest was unable to execute the actual test in the first place and has already failed on a fixture on which the test depends. Error is reserved for this. Here is another, quite concise, explanation on StackOverflow I very much liked.
Below is an example which raises an exception in the append_first fixture:
import pytest
@pytest.fixture
def order():
return []
@pytest.fixture
def append_first(order):
raise Exception
order.append(1)
@pytest.fixture
def append_second(order, append_first):
order.extend([2])
@pytest.fixture(autouse=True)
def append_third(order, append_second):
order += [3]
def test_order(order):
assert order == [1, 2, 3]
The code is from the official pytest documentation. You can also copy it from my GitHub Gist.

The result is the following:
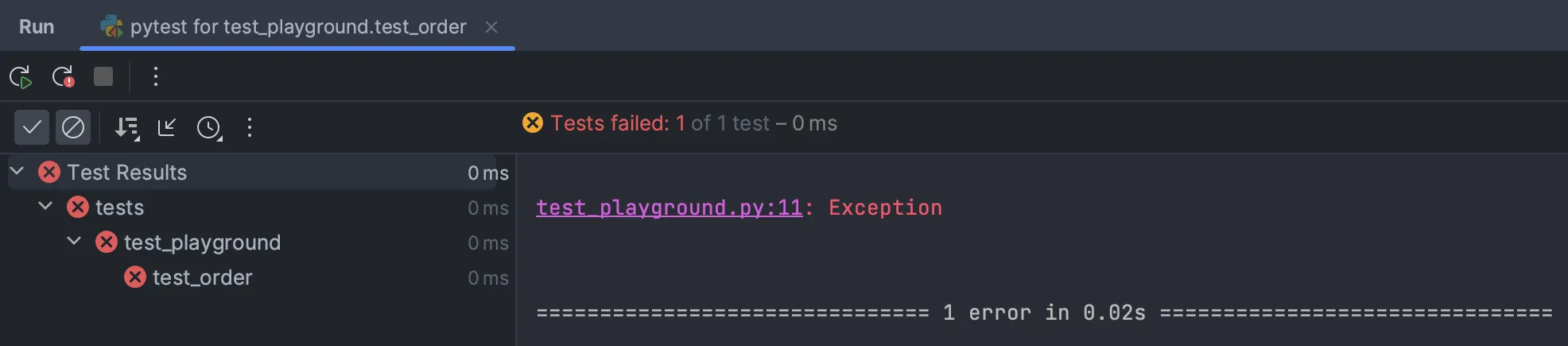
You can see the run test in PyCharm and that an error is shown. At the same time, the test is also counted as failed, which does not quite correspond to the idea of pytest. It is therefore better to read the output from pytest and not just the message from the IDE.
How do I create fixtures that are valid in other test modules?
We've seen that fixtures can be used within a module. Sometimes, however, cross-module fixtures are required, e.g a fixture for a database. You may have a wrapper for the database connection and want to test this or you have functions that indirectly use the database. One possibility is the conftest.py. The conftest.py should be placed flat in your tests folder:
tests/
├── conftest.py # Contains a db_connection_fixture
├── test_module1.py
├── test_module2.py
The advantage of conftest.py is that pytest provides an automatic discovery of fixtures within this file. The registered fixtures are then available in all modules at the same level or below without an explicit import. This can be somewhat confusing at first, as you do not know where the function parameters (fixtures) come from or where they are defined. At least PyCharm does not offer the option of navigating to the function definition with a click. However, once you know that the fixtures are in conftest.py, the advantage is that the module is cleaner, as the imports do not accumulate.
Directory structure versus conftest.py?
It is also possible to create a fixture directory and store the fixtures there. This helps with modularization and is also clearer with many fixtures. You can create a module with db_fixtures or a module with user_fixtures. Then, you can import the modules into conftest.py and they will also be included in pytest's discovery.
tests/
├── fixtures/
│ └── db_fixtures.py # Contains the db_connection fixture
├── conftest.py # Can import db_connection if needed
├── test_module1.py
├── test_module2.py
#In conftest.py:
from fixtures.db_fixtures import db_connection # Import for reuse
For a small project, I would always define the fixtures in conftest.py first and only modularize when it gets messy. The conftest.py is also important for other topics.
An example of a db_fixture would be something like this:
@pytest.fixture(scope="module")
def db_connection():
client = db.get_client(URI)
db = db.get_database(client, env_config.DB)
client.drop_database(env_config.DB)
yield db
client.drop_database(env_config.DB)
client.close()
The nice thing about this fixture is that it is valid for the scope of a module and only after a module has been processed does it continue after the yield and the database connection is closed. This has the advantage that the database can be filled with data from different functions (e.g. some inserts and then a delete).
Pytest Fixtures in Open-Source Projects
Whenever I'm not sure myself, I take a look at how well-known open source projects do it. I like to take a look at Pydantic and Streamlit 🙂. Both use pytest.
How Pydantic uses Fixtures
The Python library Pydantic not only consists of the repository of the same name, but also uses pydantic-core, which is developed in Rust. You should therefore look at both repositories if you want to understand how Pydantic tests.
Pydantic and pydantic-core mainly define their fixtures directly in the respective test modules instead of using a central conftest.py. There are currently 21 test files in Pydantic and nine in pydantic-core in which fixtures are used. The conftest.py has relatively few functions in both projects and only five fixtures in total in both projects. This organization of the tests follows the principle of high cohesion, as related test components are kept in the same modules.
Short excursion: Definitely new for me was that Pydantic, and pydantic-core, use a library called Hypothesis. Hypothesis offers property-based testing and is added to the function to be tested with the help of the decorator (@given). You have to describe what kind/types of values are allowed and Hypothesis generates random values. Here is an example from pydantic-core where different data objects are generated:
#pydantic-core: tests/test_hypothesis.py
@given(strategies.datetimes())
@pytest.mark.thread_unsafe
def test_datetime_datetime(datetime_schema, data):
assert datetime_schema.validate_python(data) == data
I didn't know Hypothesis yet, but I think it complements TDD very well and will try it out myself.
How Streamlit uses Fixtures
Streamlit does it a little differently than Pydantic and uses a mixture of e2e (end to end) testing with Playwright and unittests.
For Playwright e2e_playwright more than ten fixtures are defined in conftest.py. The remaining fixtures for pytest, which are at least as many, are defined in the modules themselves.
For the unit tests, conftest.py is defined under /lib/tests/conftest.py. It contains one fixture, the rest is defined in the modules themselves. Looking at the ratio, it seems that more weight is placed on the e2e tests.
A little excursion here too: while reading Streamlits code, I came across the testfixtures project, which is used for temporary directories. Here is the link to the still rather unknown repo.
If you're interested in the architecture, structure and software principles of open source, let me know so I can include more of it in the future!
Which Pytest Fixture parameters are useful?
The most common parameters I observe are scope, autouse, params and name. Let's go over them briefly.
Scope
The scope defines how long the fixture is valid. The default is “function”, which means that the fixture is called again and again for each test function. The alternatives are “class”, “module”, “package” and “session”. I myself often use “module” as in the example above (db_connection), so that the fixture is called once at the start of the module. The principle of the call can also be limited to class, package or session. I have also often seen session and it means that the fixture is called once for all tests in the test session.
Autouse
Is also used very often and means that the fixture is available for tests without having to pass it as a parameter.
@pytest.fixture(autouse=True)
def set_up_env():
os.environ["APP_ENV"] = "test"
#For each test, this fixture provides the environment variable
#APP_ENV with the value “test” for each test
Another example would be a fixture with autouse for a patch for a request call, that simulates communication with an API. However, I hardly ever use this as I try to mock as little as possible.
Name
name is an interesting parameter. I haven't seen many fixtures in Streamlit that use it, but I have in Pydantic. Here is an excerpt:
@pytest.fixture(scope='module', name='DateModel')
def date_model_fixture():
class DateModel(BaseModel):
d: date
return DateModel
def test_date_parsing(DateModel, value, result):
if isinstance(result, Err):
with pytest.raises(ValidationError,
match=result.message_escaped()):
DateModel(d=value)
else:
assert DateModel(d=value).d == result
The purpose of name is that the fixture is renamed to the assignment (name=). In the case of Pydantic to DateModel. This decouples the method name of the fixture from the referencing (it's referenced in test_date_parsing). It makes it quite clear that a DateModel object is passed and can then be worked with directly in test_date_parsing.
Params
A fixture is parameterized with params so that a test is run with different parameters. Here is an example, this time not from Pydantic:
@pytest.fixture(params=[1, 2, 3])
def number(request):
return request.param
def test_even(number):
assert number % 2 == 0
Final thoughts and my conclusion
pytest fixtures are part of a good test architecture. You can define them in conftest.py, in a separate directory or in the module to be tested. As soon as a fixture is cross-module, I define it in conftest.py, as this is also where the automatic discovery takes place. The open source projects Streamlit and Pydantic mainly define their fixtures in the modules where they are needed. This concept is known as High Cohesion.
You can extend your own tests with property-based testing using hypothesis. This is not directly related to the fixtures, but I found it very helpful to get to know it.
I really like using scope as a parameter and have learned the advantage of the name parameter through pydantic. I would like to use this more often, as I use pydantic very often and I like the approach of using the name of the returning model as the name of the fixture.
Finally, it should be said that pytest sometimes seems a bit magical, for example due to the automatic discovery and autouse. The learning curve is somewhat higher as a result, but pytest also abstracts work for us.
Thank you for reading! 💙 I share what I learn about software engineering (mostly Python), AI, product development, and life as a dev.
Subscribe and follow me on my journey. No spam. Unsubscribe anytime.
🤗✨ If you enjoyed this article, it would mean a lot to me if you shared it on social media or forwarded it to a friend. I write in my spare time, so any support is welcome.